Die Meisten haben bereits davon gehört, Einige haben es bereits eingesetzt aber nur Wenige haben hinter die Kulissen geschaut:
Windows Server 2012 (R2) Deduplizierung:
Schon lange ist Deduplizierung ein Thema. Zumeist zu finden im Bereich der Backup-Lösungen oder der Storageanbieter. Aber Deduplizierung auf einem Windows FileServer mit lokalen Platten? Platzsparendes Ablegen von ISO-Sammlungen, VHD-Templates oder Softwareversionen?
Mit dem Server 2012 hat Microsoft ein neues Feature eingeführt, welches es ermöglicht eben genau diese Szenarien abzubilden. In einem Blog-Beitrag stellt Microsft dar welche Einsparmöglichkeiten die Deduplizierung mit sich bringt. 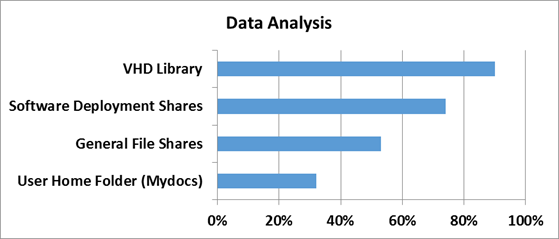
Doch was macht die Windows Server 2012 Deduplizierung eigentlich?
Transparente und Einfache Deduplizierung
Der Einsatz der Windows Server 2012 Deduplizierung ist sehr einfach. Über die Funktion „Rollen und Features“ kann der Rolle Dateiserver einfach die Funktion „Datendeduplizierung“ hinzugefügt werden. Es ist keine zusätzliche Installation oder Lizenzierung notwendig. Die Deduplizierung ist für den Nutzer volständig transparent. Es lässt sich für den Endanwender nicht feststellen, ob seine Daten dedupliziert wurden. Fordert der Nutzer eine Datei an, so erhält er sie. Alle bekannten Funktionen des NTFS-Dateisystems bleiben ohne Einschränkung bestehen und der Dedup-Vorgang filtert automatisch Dateien aus, welche nicht dedupliziert werden können. Dies könne bspw. Dateien im verschlüsselten Dateisystem (EFS) oder Dateien kleiner 32KB sein. Wird eine Datei hier ausgefiltert wird sie beim Deduplizierungsvorgang ausgelassen.
Performantes Design
Das Feature ist so designed, dass die Aktivierung der Deduplizierung keine negativen Auswirkungen auf die Performance des Systems hat. So findet die Deduplizierung beispielsweise nicht im Schreibzugriff statt. Daten fallen erst mit einem gewissen Alter in den Filter der Deduplizierung. Somit werden „heiße Daten“ zunächst ausgelassen. Dies führt zu einer optimalen Performance für aktive Daten und zu einer platzsparenden Ablage sonstiger Daten. Folgende Eigenschaften lassen sich für den Dedup-Prozess definieren:
- nachgelagerter Prozess: Daten im welche aktiv geschrieben werden werden vom Prozess zunächst ausgelassen. Der Hintergrundprozess prüft danach stündlich, welche Daten für die Deduplizierung in Frage kommen. Zuätzlich lassen sich weitere Zeitpläne für die Überprüfung konfigurieren.
- Dateialter: Es existiert eine Einstellung MinimumFileAgeDays, welche definiert wie alt eine Datei sein muss, bevor sie vom Dedup-Prozess betrachtet wird. Der Standard-Wert hierbei sind 5 Tage. Der Wert lässt sich jedoch auch auf 0 Tage herabsetzen.
- Dateityp und Speicherort Ausnahmen: Es lassen sich Ausnahmen für bestimmte Dateitypen und Speicherorte definieren. So kann die Deduplizierung zusätzlich gesteuert werden.
Portable Datenträger
Wird ein dedupliziertes Volume von einem Server an einen anderen Server portiert, oder erfolgt ein Backup des Datenträgers, so werden alle Informationen der Deduplzierung übernommen. Alle Informationen die zum Zugriff auf die Daten erforderlich sind liegen auf dem jeweiligen Volume. Einzige Voraussetzung ist, dass am Ziel die Datendeduplizierung aktiviert ist. Andernfalls sind nur nicht deduplizierte Daten zugreifbar. Die einzige Einstellung die nicht übernommen wird ist der Zeitplan, nach welchem die Deduplizierung erfolgen soll.
Ressourcen schonend
Der Deduplizierungs-Prozess ist so gestaltet, dass er möglichst im Hintergrund läuft und die produktive Arbeit des jeweiligen Systems nicht gestört wird. Stehen zum Zeitpunkt der geplanten Deduplizierung keine Ressourcen zur Verfügung, so wird der Vorgang ausgesetzt und zu einem späteren Zeitpunkt erneut gestartet. Dabei ist der sogenannte „Chunk Store Hash Index“, also die Indexierung der deduplizierten „Dateistückchen“, ist so designed, dass möglichst wenig IOPS genutzt werden. Auch dies führt zu einem performanten Betrieb.
Datei-Stückelung (Chunking)
Die Deduplizierung zerteilt die Daten in Stücke von 32-128 KB Größe. In der Regel wird eine Größe von 64 KB verwendet. Die zerteilten und komprimierten Chunks werden dann im versteckten Ordner „System Volume Information“ abgelegt. Die ursprüngliche Datei wird dabei durch einen Pointer ersetzt. Über diesen Pointer werden alle Chunks referenziert, welche zum Zusamensetzen der Datei benötigt werden. Man hat also beispielsweise zwei Dateien: 
nach der Verarbeitung sieht das Ganze dann so aus: 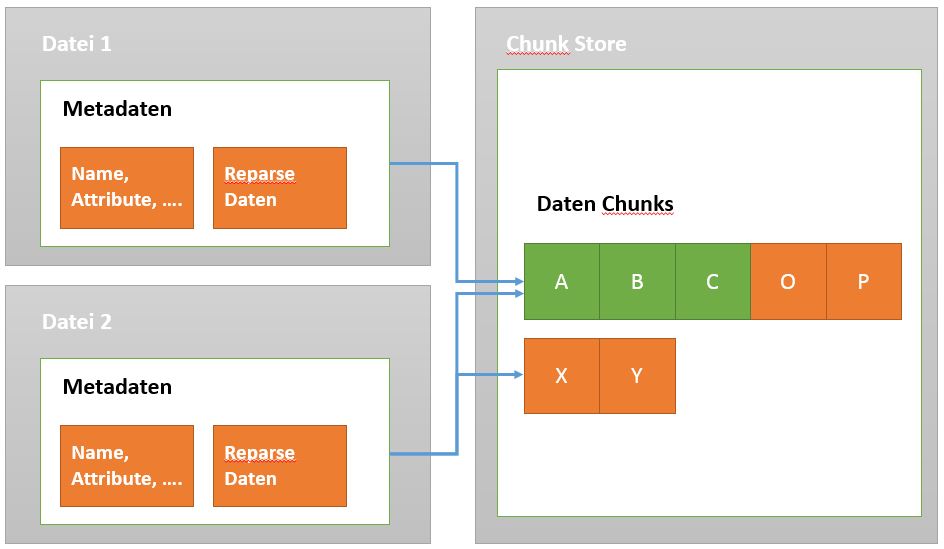
Branch Cache Integration
Wird im Unternehmen Branch Cache verwendet, so greift dieses Feature auf die Chunks und den entsprechenden Index zu. Somit können remote angeforderte Dateien schneller übertragen werden, da nur die komprimierten Chunks über die WAN-Strecke gehen. Dies führt zu einer spürbaren Entlastung der WAN-Strecke.
Doch wie wirkt sich die Dedulpizierung auf den Datenzugriff aus?
Die Deduplizierung fragmentiert die Dateien und legt die Chunks verteilt über die Festplatte ab. Dies würde zu längeren Suchzeiten führen. Daher versucht der Filter Treiber während der Dateiverarbeitung die Chunks einer Datei möglichst am gleichen Ort abzulegen. Somit ist der Vorgang nicht vollständig wahlfrei. Zudem verfügt die Deduplizierung über ein Caching, so dass das wiederholte aufsuchen von Chunks vermieden wird. Zudem hat das darüberligende Dateisystem eine weitere Caching-Funktion. Greifen mehrere Nutzer ähnliche Dateien zur gleichen Zeit zu, wird der Datenzugriff durch das Caching beschleunigt. Folgende Aussagen trifft Microsoft hierbei:
- Es gibt keine spürbaren Unterschiede beim zugriff auf Office Dokumente und der Nutzer merkt nicht, ob Deduplizierung aktiviert ist
- Wenn eine einzelne große Datei kopiert wird, kann sich die Kopierzeit um den Faktor 1,5 verlängern
- Wenn mehrere große Dateien kopiert werden, kann durch das Caching eine bis zu 30% geringere Kopierzeit erreicht werden.
- Mit einem Lasttest für FileServer (File Server Capacity Tool), welcher einen gleichzeitigen Zugriff von 5000 Nutzern simuliert, ist nur eine Reduzierung um 10% in Bezug auf die durch SMB 3.0 unterstützen User feststellbar.
Zuverlässigkeit und Risiko Betrachtung
Durch die Verwendung der Deduplizierung wird das Risiko durch beschädigte Dateien potenziell höher. Da ein einzelner Chunk von vielen Dateien referenziert sein kann, würde somit eine Beschädigung oder Korruption dieses Chunks zu einem erheblichen Datenverlust führen. Daher gilt es hier entsprechende Vorkerhungen zu treffen.
- Backup Unterstützung: Microsoft supported ein vollständig optimiertes Backup über das integrierte Windows Server Backup. Zudem verfügen diverse Drittanbieter über Backup-Tools, welche die deduplizierten Daten sichern können.
- Reporting und Erkennung: Immer wenn der Deduplizierungs-Filter eine korrupte Datei findet, wird dies im Event-Log dokumentiert. Somit sollte das Event-Log dringend im Monitoring eingebunden und überwacht werden. Bei jeglichem Lese- und Schreibzugriff werden die Checksummen der Daten und Metadaten abgeglichen. Somit ist eine frühzeitige Erkennung von korrupten Bereichen möglich.
- Redundanz: Wird ein Chunk mehr als 100 mal referenziert, so wird eine oder mehrere zusätzliche Kopien abgelegt. Dieser Bereich wird „Hotspot“ genannt und stellt eine Sammlung der wichtigsten Chunks dar.
- Reparatur: Ein wöchentlicher Aufräum-Job untersucht das Event-Log hinsichtlich dokumentierter Korruptionen und behebt diese durch Kopien redundanter Chunks, sofern verfügbar. Werden Storage Spaces mit einem gespiegelten Pool verwendet, so wird versucht auf der gespiegelten Seite eine valide Datei zu erhalten. Andernfalls muss die Datei aus dem Backup wiederhergestellt werden. Zudem werden neu hinzukommende Chunks dahingehend geprüft ob sie die korrupte Datei ersetzen können.
Quellen:
Introduction to Data Deduplication in Windows Server 2012 – TechNet Blog
Eliminating Duplicated Primary Data
Microsoft TechNet
Ähnliche Beiträge


Leave a comment